クラウドのAIコーディング支援は便利ですが、API料金やソースコードの外部送信、通信待ちが気になることもあります。そこで今回は、WindowsホストでローカルLLMを動かし、VMware上のLinux仮想環境でOpenCodeを使う構成をまとめます。
今回のポイントは2つあります。ひとつは、OpenCodeをWSLではなくVMware上のLinuxゲストで動かしていること。もうひとつは、gpt-oss:20b-128k をOllamaの標準タグとしてそのまま使うのではなく、ベースモデルを取得したあとにカスタマイズして作成した独自の運用モデルとして使っていることです。
ローカルLLM環境は、うまくハマるとかなり快適です。ただし、モデルによってはツール呼び出しが不安定だったり、ファイルを作成したと言いながら実際にはできていなかったり、権限設定を無視したような挙動を見せることもあります。この記事では、そのあたりも含めて現実的に整理していきます。
OpenCodeとは
OpenCodeは、ターミナルで動くオープンソースのAIコーディングエージェントです。単なるチャットツールではなく、コードを読んだり、ファイルを編集したり、コマンドを実行したりしながら作業を進められるのが特徴です。
また、OpenCodeはクラウドAPI専用ではありません。OpenAI互換APIを提供できる推論サーバーがあれば、Ollamaやllama.cppのようなローカル推論基盤とも組み合わせられます。つまり、ローカルLLMを活用した自前のAI開発環境を作りやすいわけです。
今回の構成
今回の記事で扱う構成は以下の通りです。
- Windowsホスト
- Ollamaを起動
- 必要に応じてllama.cppの
llama-serverも起動 - ローカルLLM本体をWindows側で管理
- VMware上のLinux仮想環境
- OpenCodeをインストール
- OpenCodeの設定ファイルを作成
- Windowsホスト上のOllama / llama.cppへHTTPで接続
OpenCode公式ではWindows利用時にWSLが案内されていますが、Linux版も使えるため、実運用としてVMware上のLinuxゲストで構築する形でも十分成立します。むしろ、すでにVMware環境を持っているなら、そのまま流用したほうが自然です。
なぜOpenCodeを仮想のLinux側に置くのか
OpenCodeのようなAIコーディングエージェントは、Linux環境との相性が良いです。シェルやパッケージ管理、権限まわりの扱いが安定しやすく、実務でもLinux前提の操作をそのまま試しやすくなります。
ただ、今回あえてVMware上のLinux仮想環境に置いている理由は、それだけではありません。もうひとつ大きいのがセキュリティと切り戻しのしやすさです。OpenCodeは設定次第でファイル編集やbash実行を伴うため、モデルの調子が悪いと、意図しない編集や不要なコマンド実行につながる可能性があります。OpenCode自体も permission で実行可否を制御する設計になっており、こうした操作リスクを前提に運用するツールだと考えたほうが安全です。
そこで、OpenCode本体はホストのWindowsに直接置かず、仮想のLinux側へ分離しています。こうしておくと、万一AIエージェントが暴走したり、不要な変更を加えたりしても、影響範囲を仮想マシン側に寄せやすくなります。つまり、モデルはWindows、作業領域は仮想Linuxと分けることで、利便性と安全性のバランスを取りやすくなります。
さらにVMwareを使う利点は、スナップショットである時点の状態を残しておけることです。事前にスナップショットを取っておけば、設定を壊したり、不要な変更を大量に入れたりした場合でも、以前の状態へ戻しやすくなります。AIエージェントを使った検証では、「うまくいったら採用、危なければ巻き戻す」という運用がしやすいのは大きな安心材料です。
もちろん、スナップショットがあれば何でも安全というわけではありません。スナップショットは切り戻しには便利ですが、バックアップや完全な防御策の代わりではありません。実際の運用では、OpenCode側の permission を厳しめに設定し、必要に応じて仮想マシンのネットワークも絞り、危険な操作を最初から通しにくくしておくのが基本です。
たとえばVMware Workstationでは、ホストオンリーやNATといったネットワーク構成を使い分けられます。ローカル検証が中心なら、むやみに外へ開かず、必要最小限の通信に留める構成のほうが扱いやすいです。OpenCodeのWeb機能も、標準では 127.0.0.1 にバインドされ、ネットワーク公開時はパスワード設定が推奨されています。
要するに、仮想Linux上でOpenCodeを動かす理由は、単なる“Linuxのほうが動かしやすい”だけではありません。AIに作業を任せる以上、ホストOSから一段隔離し、permissionで抑え、最悪はスナップショットで戻せる構成にしておくこと自体が、実用的なセキュリティ対策になります。
gpt-oss:20b-128k はどう作ったか
今回使う gpt-oss:20b-128k は、Ollamaから取得したベースモデルをそのまま使っているわけではありません。Ollamaでダウンロードしたモデルを、Modelfileでカスタマイズして作成した独自モデル名という扱いです。
OpenCode系のツールは、コード・会話履歴・実行結果・権限確認などをまとめて持つため、コンテキスト長が短いと不安定になりやすいです。そのため、ベースの gpt-oss:20b を元に、num_ctx を広げた運用用モデルとして作っておくと扱いやすくなります。
1. ベースモデルを取得する
ollama pull gpt-oss:20b2. Modelfileを作成する
たとえば、以下のようなModelfileを用意します。
FROM gpt-oss:20b
PARAMETER num_ctx 131072
PARAMETER temperature 0.2
"""ここではコンテキスト長を128k相当に広げつつ、温度をやや低めにして、コーディング用途で暴れにくい方向へ寄せています。
3. カスタムモデルとして作成する
ollama create gpt-oss:20b-128k -f Modelfileこれで、OpenCode側からは gpt-oss:20b-128k という名前のローカルカスタムモデルとして指定できます。記事中でこのモデル名を使う場合は、Ollama公式の配布タグではなく、自分で作成した運用モデル名であることを書いておくと誤解がありません。
VMware上のLinux環境にOpenCodeをインストールする
OpenCodeはLinuxでも利用できるため、VMware上に用意したUbuntuやDebian、RHE系のRocky等へインストールして使えます(今回はRocky9を使用しました)。ホストOSがWindowsでも、OpenCode自体はゲストOS側のLinuxで動かすイメージです。
Linuxゲスト側で以下を実行します。
curl -fsSL https://opencode.ai/install | bashインストール後は、シェルを再読み込みして opencode コマンドが使えるか確認しておくと安心です。
OpenCodeの設定ファイル例
設定ファイルは、Linux環境なら ~/.config/opencode/opencode.jsonc のような場所で管理すると扱いやすいです。JSONCにしておけば、コメント付きで残せるので試行錯誤しやすくなります。
以下は、Windowsホスト上のOllamaおよびllama.cppへ接続する設定例です。IPアドレス部分は、VMwareゲストから見えるWindowsホストのアドレスに置き換えてください。
{
"$schema": "https://opencode.ai/config.json",
"permission": {
"*": "ask",
"edit": "ask",
"list": "allow",
"bash": {
"*": "ask",
"grep *": "allow",
"git *": "ask",
"npm *": "ask",
"rm *": "ask"
},
"webfetch": "ask"
},
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Ollama (local)",
"options": {
"baseURL": "http://サーバーアドレス:11434/v1"
},
"models": {
"gpt-oss:20b-128k": {
"name": "gpt-oss:20b-128k"
},
"qwen3.5:27b": {
"name": "qwen3.5:27b"
},
"qwen3.5:9b": {
"name": "qwen3.5:9b"
},
"qwen3-coder:30b": {
"name": "qwen3-coder:30b"
},
"granite4:3b-128k": {
"name": "granite4:3b-128k"
}
}
},
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server",
"options": {
"baseURL": "http://サーバーアドレス:8080/v1"
},
"models": {
"GPT-OSS-Swallow-20B-RL-v0.1-Q4_K_M.gguf": {
"name": "GPT-OSS-Swallow-20B",
"limit": { "context": 32768, "output": 2048 }
}
}
}
},
"model": "ollama/gpt-oss:20b-128k",
"small_model": "ollama/granite4:3b-128k"
}この設定で重要なのは、permissionを厳しめにしていることです。ローカルLLMではモデル差が大きく、最初から何でも許可すると事故につながりやすくなります。少なくとも初期段階では、edit や bash を都度確認にしておいたほうが安全です。
llama.cppを使うときの考え方
Ollamaだけでなく、llama.cppの llama-server をOpenAI互換APIサーバーとして使う構成もあります。GGUF系モデルを使いたい場合や、量子化済みモデルを細かく試したい場合はこちらが便利です。
ただし、OpenCode側のモデルIDは、実際にサーバー側で見えている名前に合わせる必要があります。特にllama.cpp側は、起動方法や公開名によって設定上の名前がズレやすいため、ここは地味にハマりやすいポイントです。
opencode webでブラウザ実行する方法
OpenCodeはTUIだけでなく、opencode web でブラウザUIからも使えます。
基本の起動はシンプルで、Linux仮想環境側で次を実行するだけです。
opencode webopencode web を実行すると、ローカルサーバーが起動し、ブラウザでOpenCodeのWeb画面を開けます。今回のOllama / llama.cpp構成でも、すでに設定済みの provider や model をそのまま使えるため、TUIとは別画面で同じローカルLLM環境を操作できます。
ポートや待受アドレスを明示したい場合は、次のように指定できます。
opencode web --port 4096
opencode web --hostname 0.0.0.0 --port 4096ただし、0.0.0.0 で待ち受けてネットワーク越しに使う場合は注意が必要です。ローカル確認だけならそのままでもよいですが、他端末からアクセス可能にする場合は、少なくともパスワード保護を有効にしておいたほうが安全です。
OPENCODE_SERVER_PASSWORD=your-password opencode web --hostname 0.0.0.0 --port 4096必要に応じて、--mdns や --cors も使えます。ブラウザ中心で操作したいときや、TUI表示が端末依存で不安定なときは、opencode web を試す価値があります。
なお、Web UI と TUI は排他的ではありません。先にWeb側を起動しておけば、別端末から attach して同じ状態を共有しながら使うこともできます。
opencode web --port 4096
opencode attach http://localhost:4096ローカルLLMでOpenCodeを使うメリット
- API従量課金を気にしにくい
- コードやメモを外部サービスに毎回送らずに済む
- モデルを自由に差し替えられる
- 大きいモデルと小さいモデルを用途別に使い分けやすい
- ローカル環境に合わせてコンテキスト長や挙動を調整しやすい
たとえば、重めのコード読解や修正は gpt-oss:20b-128k や qwen3-coder:30b、軽い要約や補助タスクは granite4:3b-128k のように分けると、体感も負荷も変わります。
ローカルLLMでOpenCodeを使うデメリット
一方で、ローカルLLMは万能ではありません。ここはかなり大事です。
- モデルによってはツール呼び出しが不安定
- ファイルを作成したと言いながら、実際にはできていないことがある
- 権限設定を無視したような挙動に見えるケースがある
- 途中で暴走して、関係ない編集や長文出力に進むことがある
- 日本語が自然でも、ツール適性が弱いモデルは普通にある
特に危ないのは、返答はもっともらしいのに、実際の処理が伴っていないケースです。これはローカルLLMでは珍しくありません。OpenCodeが「ファイルを作成しました」と返してきても、実ファイルや差分を確認すると存在しない、ということは普通にありえます。
また、 通常であれば権限設定に沿って
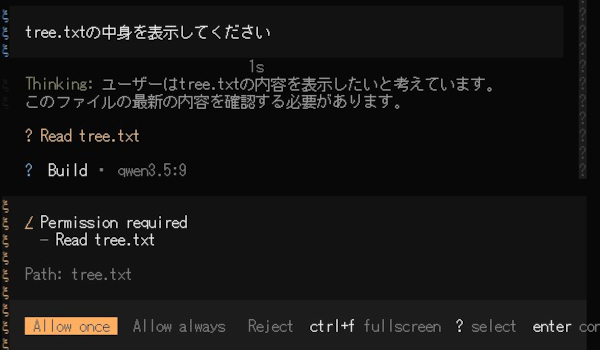
安定運用のためのコツ
1. まずは読み取り中心で試す
最初から大規模な編集や削除を任せるのではなく、list、grep、read が安定するかを先に確認し、その後で edit や bash を段階的に許可するのがおすすめです。
2. permissionは甘くしすぎない
ローカルLLMの癖が読めるまでは、edit、rm、bash は都度確認にしておいたほうが安全です。最初から自動実行を広げると、誤動作時の被害が大きくなります。
3. モデル名の不一致を疑う
OpenCodeの設定で指定したモデル名と、Ollamaやllama.cpp側で実際に見えているモデル名がズレると動きません。とくにカスタムモデルは、自分で付けた名前をそのまま設定に合わせる必要があります。
4. コンテキスト長は広めを意識する
OpenCode系では、コード・履歴・ツール結果をまとめて扱うため、コンテキスト不足がそのまま不安定さにつながりやすいです。64k以上をひとつの目安にしつつ、余裕があるなら128kクラスで試す価値があります。
5. 実結果を必ず確認する
ファイル作成、編集、削除、コマンド実行については、AIの返答だけで信用しないことが大事です。差分、生成物、実ファイル、ログを自分でも確認する運用にしておくと事故が減ります。
VMware構成での注意点
VMwareゲストからWindowsホスト上のOllamaやllama.cppへ接続するため、ゲストOS側からホストの 11434 番や 8080 番へ到達できるようにしておく必要があります。
このあたりは、NAT・ブリッジ・ホストオンリーのどれを使っているかで見え方が変わります。ローカル検証なら閉じたネットワークで十分ですが、社内PCや共有環境で使う場合は、公開範囲やファイアウォール設定に注意してください。
まとめ
OpenCodeをローカルLLMで使うなら、WindowsホストでOllama / llama.cppを動かし、VMware上のLinux仮想環境でOpenCodeを使う構成はかなり現実的です。
今回のポイントは、gpt-oss:20b-128k を「Ollamaから取得したモデルを自分でカスタマイズして作った運用モデル」として説明すること、そしてLinux環境をWSLではなく実際のVMware構成に合わせて書くことです。
ローカルLLMはコスト面や自由度で非常に魅力がありますが、モデルによってはツール呼び出しや権限順守がかなり不安定です。だからこそ、最初は厳しめのpermissionで小さく試し、安定したモデルだけを残していくのが失敗しにくい進め方だと思います。
タグ
OpenCode, opencode, ローカルLLM, Ollama, llama.cpp, VMware, Linux仮想環境, Windows, AIコーディング, AIエージェント, Modelfile, OpenAI互換API, gpt-oss, qwen3-coder



